V poslednej dobe je na SETI fórach veľký ruch okolo aplikácie pracujúcej na GPU od firmy NVIDIA. Táto aplikácia aj napriek minimalnej optimalizácií vykazuje viac ako dvojnásobný výkon pri použití už teraz viacmenej low-endovej GPU 9600GT oproti v8 optimalizovanej CPU verzie na AMD Phenom (moje osobné merania). Prečo začali byť grafické karty v centre záujmu vývojárov?
GPU = masívne paralelný procesor
Keď sa objavila verzia DirectX 8 ktorá implementovala takzvané vertex a fragment shadery verzie 1a, nikto nepredpokladal, že budú základom pre dnešné HPC (High Performance Computing). Prvá verzia umožňovala iba jednoduché výpočty - využívala sa na výpočty osvetlenia scén v hrách. Ale s príchodom druhej generácie v DirectX 9 a následne ich daľšom zdokonalení v DirectX 9c začali niektorí vývojári uvažovať nad ich využitím aj na iné účely ako len na hry. Kedže v herných enginoch dokázali neskutočné veci (Quake III,RTCW....), nebolo by ich možné použiť aj na riešenie bežných, výpočtovo náročných úloh?
Pre programátorov hier tu boli dve cesty - buďto použili univerzálny kompilátor HLSL (High Level Shader Language) od Microsoftu, ktorý generoval priamo strojový kód pre GPU procesory, ale ktorého výkonnosť závisela od implementácie jednotlivých výrobcov, alebo použil jazyk Cg , ktorý vyvinuli v NVIDII. Cg podporuje obrovské množstvo platforiem počnúc DirectX 8, 9, 10, OpenGL 1.x.2, GLSL, dokonca fp a vp profily pre staručké GeForce 3!!! Cg je tiež vybavený kompletnou runtime knižnicou s množstvom funkcií. Nevýhodou oboch jazykov je zložitý manažment okolo vstupno-výstupných dát.
Prvým pokusom zjednodušenie (a aj úspešným) bola adaptácia jazyka brook+ na GPU (brookGPU ). Tento jazyk využíva vlastný preprocesor na generovanie C++ zdrojového pseudokódu pre takzvané backendy. BrookGPU podporuje momentálne tieto backendy : DirectX, OpenGL/GLSL, CTM a multicore. Pre DirectX sa používa HLSL (je univerzálny), pre OpenGL/GLSL Cg, preto je OpenGL backend vhodnejší pre použitie na NVIDIA GPU. CTM je prostredie pre ATI GPU. A multicore je backend pre viacjadrové CPU, ale je nutné podotknúť že nedosahuje ani zďaleka výkonnosti GPU backendov. BrookGPU ako prvý ukryl zložitosť správy dát na GPU za jednoduchý systém streamov a výkonných častí kernelov. Jednoducho ste si zadefinovali vstupné a výstupné streamy, napísali ste jednoduchý kernel a o ostatné sa už postaral samotný prekladač. Už pred niekoľkými rokmi boli pokusné implementácie napr. nasobenia matíc niekoľkonásobne rýchlejšie na GPU (GeForce7600) ako na vtedajších CPU (P4).
Pred dvoma rokmi sa objavila nová, ešte všeobecnejšia implementácia pre výpočty na GPU - CUDA (Compute Unified Device Architecture) . CUDA (podporovaná na GPU 8xxx a novších) umožňuje pracovať s GPU ako s klasickým CPU, samozrejme s prihladnutím na rozdiely medzi paralelnou architektúrou GPU a superskalárnou architektúrou CPU. Doteraz GPU pracovali iba s tzv. single precision (32-bitové číslo), posledné generácie (GTX2xx) podporujú už double precision (64-bit číslo). CUDA je postavená na tzv. thread modeli - istý počet výkonných jednotiek spracúva veľké množstvo vláken, pričom jedno vlákno vykonáva nejakú činnosť na malom množstve dát.
SETI MultiBeam bežiaci na GPU
Čo z toho plynie pre SETI? Kód SETI klienta môžme rozdeliť na 5 sekcií: chirping, FFT, PowerSpectrum, SpikeFind a PulseFind. V časti chirping sa modifikujú pôvodné dáta o tzv. dopplerov effekt - čiže o posun spektra spôsobený možnou rotáciou zdroja. Toto sa musi urobiť na 1048576 ks dát. Ide vlastne o rozklad vektora na jeho komplexnú podobu plus deformácia spôsobená dopplerovým efektom, použitím funkcií sin() a cos(). Ak uvážite, že aj tie najrýchlejšie implementácie týchto funkcíí na CPU prekračujú 10 taktov, tak GPU ich vypočíta za 4 takty, pre štyri čísla naraz na 64 procesoroch (9600GT). Ide o neuveriťeľné zrýchlenie operácií. Podobne FFT (Fast Fourier Transformation) je niekoľkonásobne rýchlejšia na GPU ako na CPU
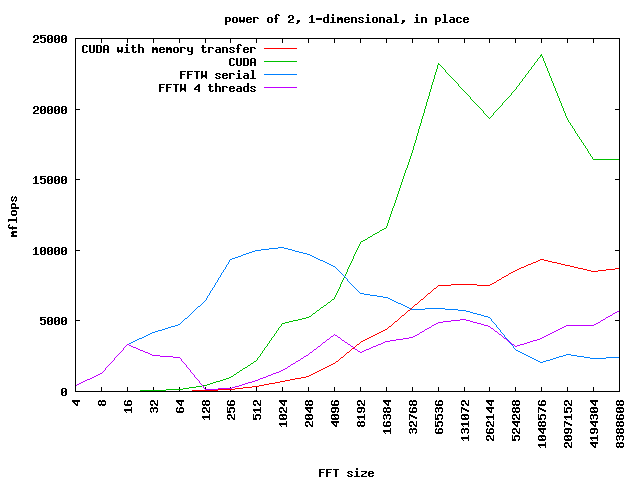
CUDA implementácia je pre veľké veľkosti FFT až 5x rýchlejšia ako FFTW implementácia na CPU. (Zdroj: www.science.uwaterloo.ca)
PowerSpectrum je len jednoduchý výpočet veľkosti vektora, urýchlený podobným spôsobom ako chirping. Spike find je hľadanie maxima v poli. Hlavným zrýchlením je to, že v pôvodnej implementácií sa FFT, powerspectrum a spikefind robili po častiach veľkých ako FFT, kdežto vďaka CUDA architektúre spracujete tieto úlohy naraz v jednej dávke. Príklad:
- spraviť chirping;
- vypočítať FFT=8;
- vypočítať PowerSpectrum bloku o veľkosti 8;
- nájsť tomto bloku maximum (spikefind);
- bod 2-4 opakovať 131072 krát;
- potom pokračovať na pulsefind;
Kdežto CUDA verzia to rieši takto:
- spraviť chirping;
- vypočítať NARAZ 131072 FFT pre veľkosť 8;
- vypočítať NARAZ celé PowerSpectrum (1048576 ks)
- nájsť NARAZ maximá vo všetkých 131072 blokoch o veľkosti 8 (spikefind);
- potom pokračovať na pulsefind;
Samotný pulsefind je najmenej efektívna časť - už jeho definícia spôsobuje problémy s paralelnou implementáciou. Táto časť pomerne zložitým algoritmom hľadá tzv triplet pulses (silné impulzy) a po nej prehľadáva celé spektrum tzv. "fast folding" algoritmom na slabé, ale pravidelne sa opakujúce pulzy (viac info na Classic SETI@Home).
A aký výkon má aplikácia na reálnych dátach? Grafy hovoria za všetko :
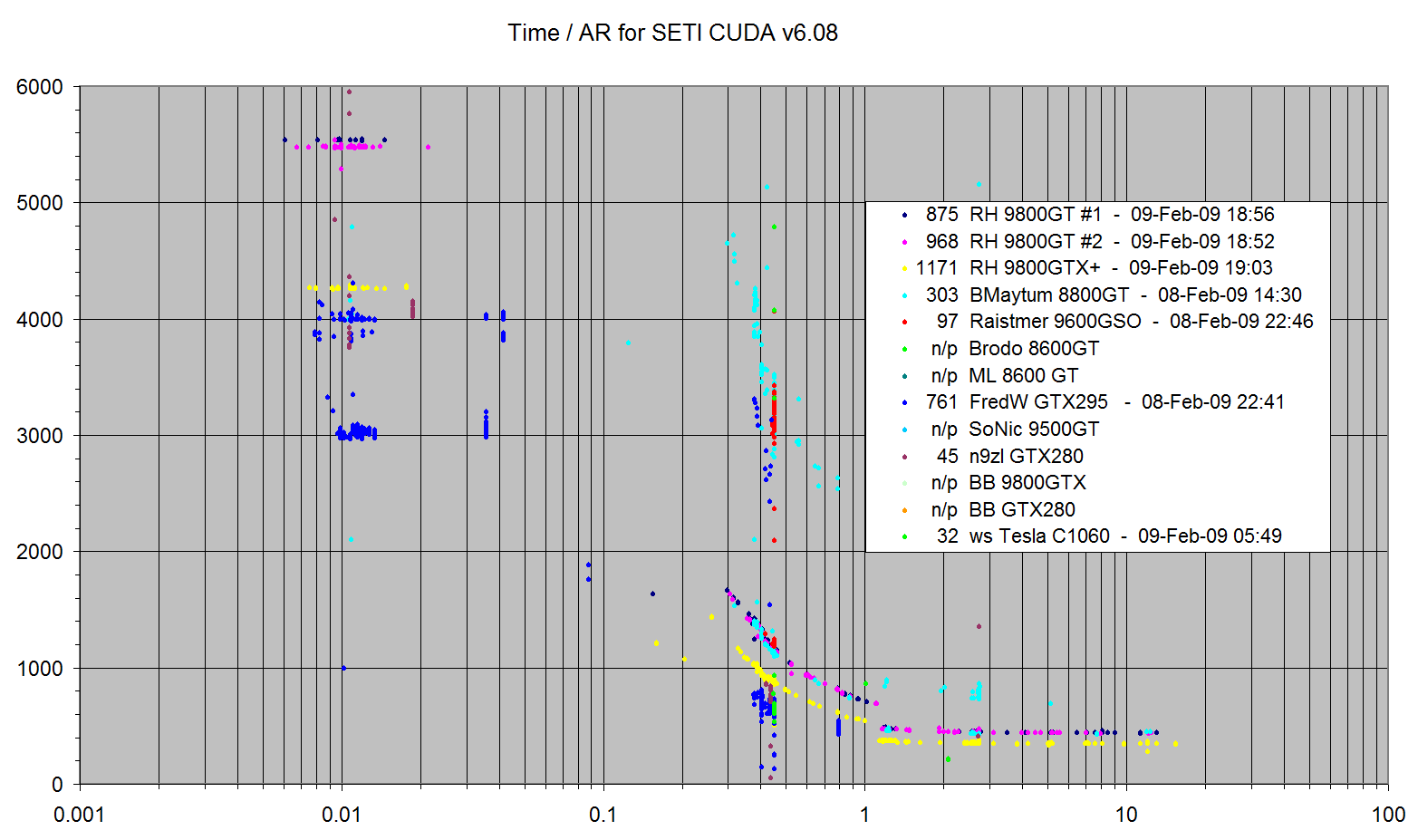
Farby určujú rôzne typy GPU, vodorovne je AR (Angle Range) jednotiek, zvislo čas na ich spracovanie. Ako vidno, jednotky s veľmi malým AR, tzv. VLAR (Very Low Angle Range), vykazujú práve kvoli neefektívnosti pulsefindu veľké časy spracovania. Preto sa používa tiež modifikovaná verzia, ktorá automaticky jednotky VLAR odmietne spracovať a vrati ich serveru naspäť s chybou, čím ich server následne pošle niekomu inému na spracovanie. Bolo by dobré keby takéto jednotky možno automaticky chodili iba klientom bežiacim na CPU.
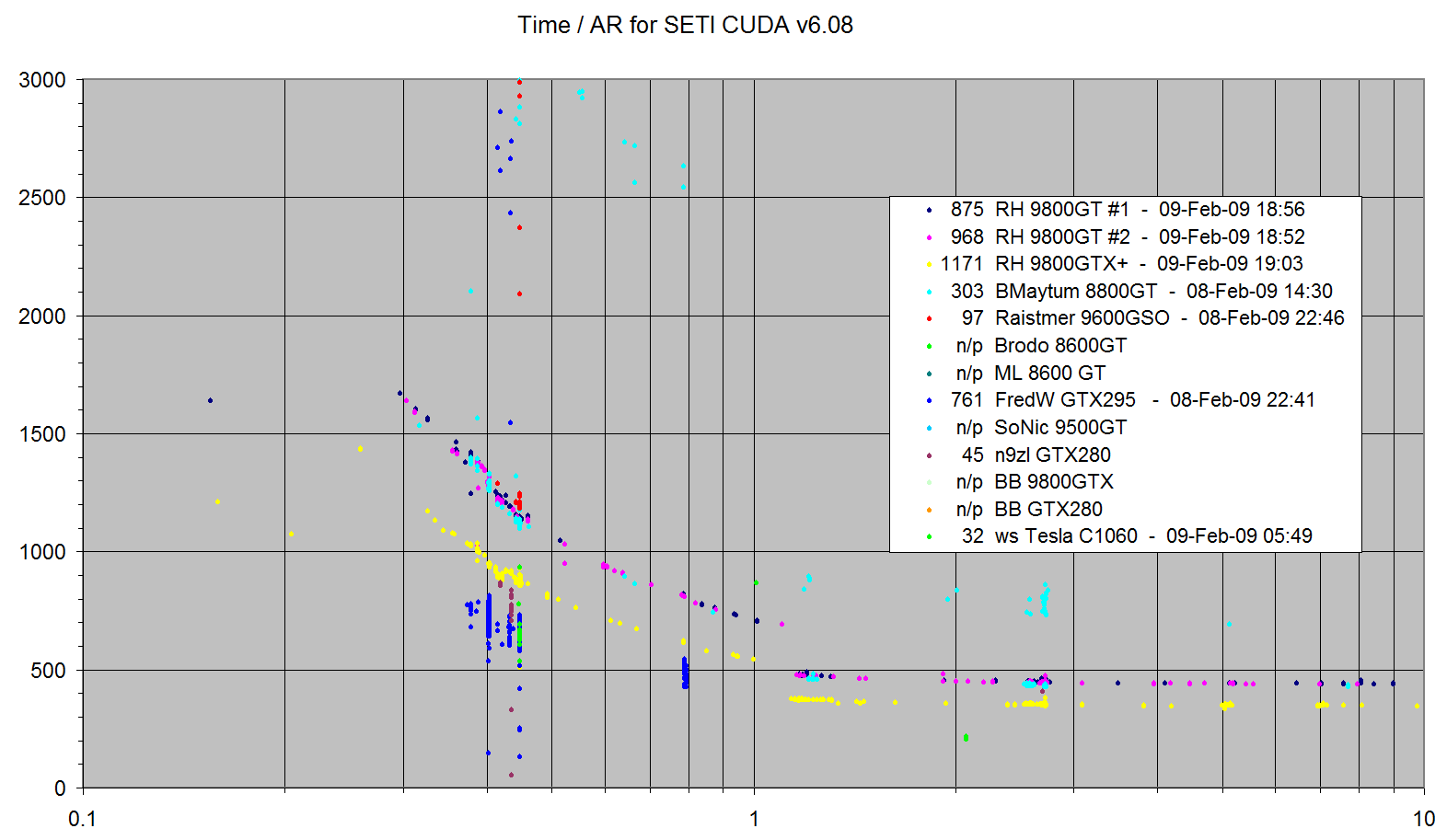
Legenda je rovnaká s predchádzajúcim obrázkom, len tu sú výsledky modifikovanej aplikácie (VLAR jednotky vracia serveru).
Čo dodať? Keď sa podarí zefektívniť implementáciu pulsefindu, môžme očakávať ešte lepšie výsledky. Podotýkam, že aplikácií na GPU môže bežať toľko, koľko máte CUDA GPU - najlepšie stroje v SETI sú postavené na najvýkonnejších grafických kartách, napr. momentálne (marec 2009) vedúci host v SETI štatistikách je osadený šiestimi GPU...
- Ak chcete pridať komentáre, tak sa musíte prihlásiť
- prečítané 9944x
-